Listen to NavamAI Podcast
Compare Models¶
NavamAI comes with configurable support for more than 15 leading models from five providers (Ollama, Anthropic, OpenAI, Groq, Google). The navamai test command can be used to run each of the navamai commands over all the provider and model combinations and respond with a summary of model test and evaluation results. Use this to quickly compare models and providers as well as when you add or remove a new model or provider in the config.
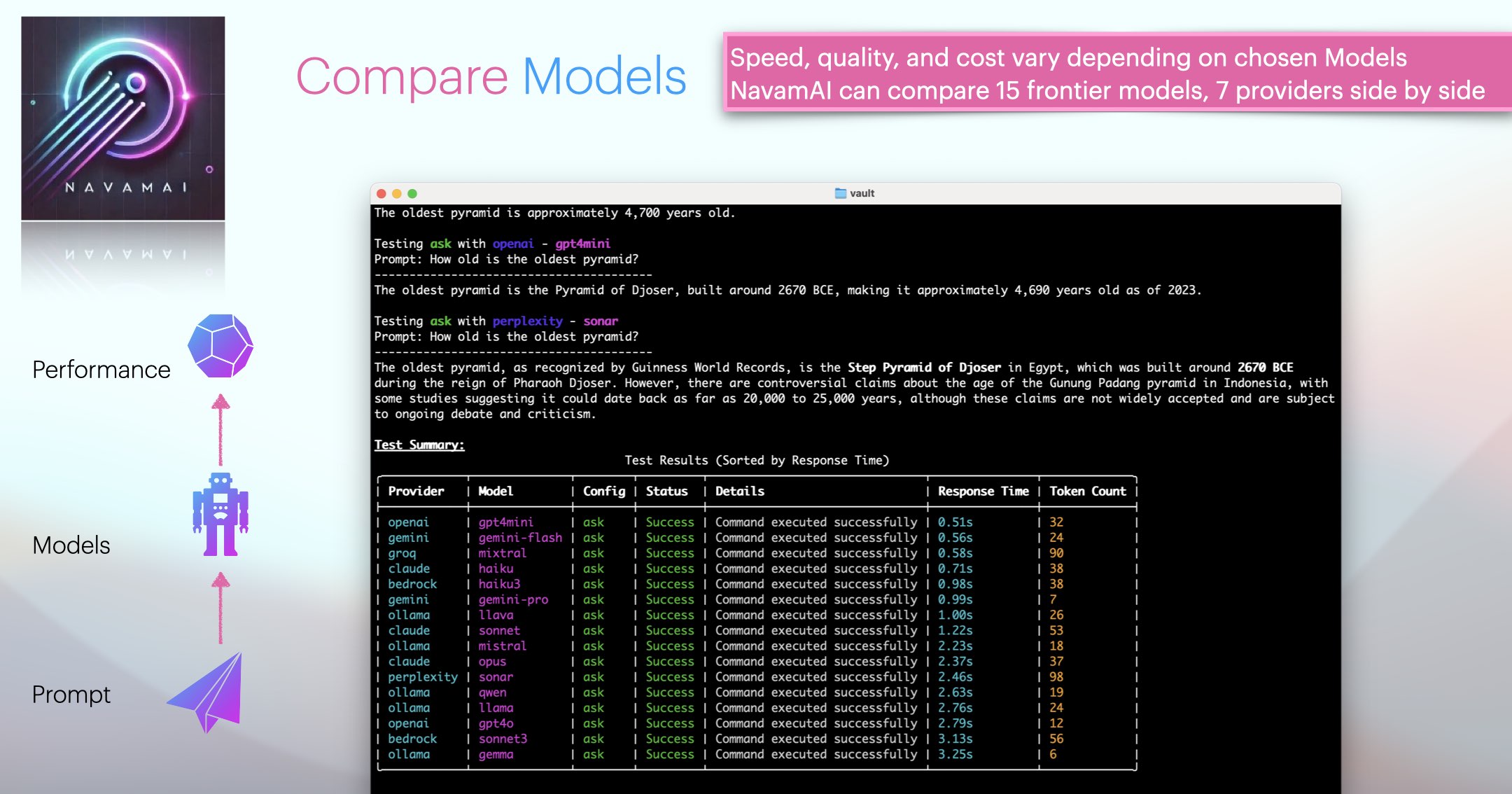
This command is super useful when comparing model response time (latency), response quality (does it follow the system and prompt instructions), response accuracy, and token length (cost) for the same prompt. You can configure the test prompts within navamai.yml in the test section.
Run multiple models side by side¶
Want to compare multiple models side by side? All you need to do is open multiple shells or Terminal instances. Now in each of these, one by one, change the model, run same ask "prompt" and compare the results side by side. Simple!


As NavamAI commands use the navamai.yml config in the current folder every time they run, you can create more complex parallel running, multi-model and cross-provider workflows by simply copying the config file into multiple folders and running commands there. This way you can be running some long running tasks on a local model in one folder and terminal. While you are doing your day to day workflow in another. And so on.
Test and Evaluate Models and Providers¶
NavamAI comes with configurable support for more than 15 leading models from five providers (Ollama, Anthropic, OpenAI, Groq, Google). The navamai test command can be used to run each of the navamai commands over all the provider and model combinations and respond with a summary of model test and evaluation results. Use this to quickly compare models and providers as well as when you add or remove a new model or provider in the config.
This command is super useful when comparing model response time (latency), response quality (does it follow the system and prompt instructions), response accuracy, and token length (cost) for the same prompt. You can configure the test prompts within navamai.yml in the test section.

Here is an example of running navamai test vision command and resulting test summary. I this default prompt and image we are sharing image of around 150-160 people standing in close proximity in a circle and asking the model to count the number of people. The right number is between 150-160. This can be used to calculate the relative accuracy of each model based on the response. How closely the response follows the system prompt and the user prompts is indicative of quality of response.
You can also notice the response times seem proportional to model size. For Claude, Opus > Sonnet > Haiku. For Gemini, Pro > Flash. For OpenAI, GPT-4o > GPT-4-mini.
You can similarly run navamai test ask command to test across all models and providers. In this run you may find groq is among the fastest providers when it comes to response time.
Of course, you may need multiple test runs to get better intuition of response times as there are multiple factors which effect latency other than model size or architecture, like network latency, which may change across multiple test runs.